K平均法(K-MEANS)
K平均法は、データをK個のクラスタに分割するための強力な手法です。このアルゴリズムは、各データポイントを最も近いクラスタの中心に割り当てることで、データの構造を明らかにします。K平均法は、特に大規模なデータセットに対して効率的に動作し、視覚化やパターン認識のための基盤を提供します。さらに、K平均法は異なる分野での応用が可能で、マーケティング分析や画像処理、さらには生物情報学においても重要な役割を果たしています。この手法を用いることで、データの隠れた関係性を発見し、意思決定をサポートすることができます。
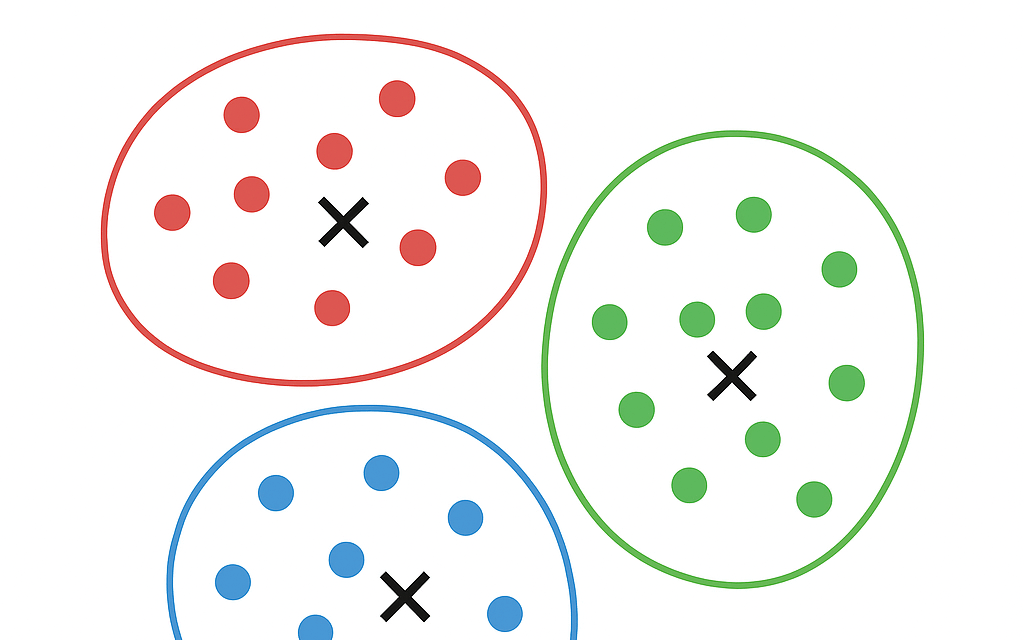
クラスタリングとは正解のないデータから共通する特徴を持つグループに分類することです。教師なし学習のクラスタリングは教師ラベルがないので、データ内部の特徴に基づいてグループに分けるようにモデルを学習させます。K平均法はデータからグループ構造を見つけ出すためにデータをK個のクラスタに分けることです。
K平均法の手順
- 初期的にデータをランダムにK個のクラスタに分ける
- 各クラスタのデータ点の重心を求める
- 各データ点と計算されたK個の重心の距離を計算する
- 各データ点に距離が一番近い重心に対応するクラスタを割り当て直す
- 重心の位置が変化しなくなるまで2〜4を繰り返す



{kind=link}